Czym różni się Machine Learning od Deep Learningu?
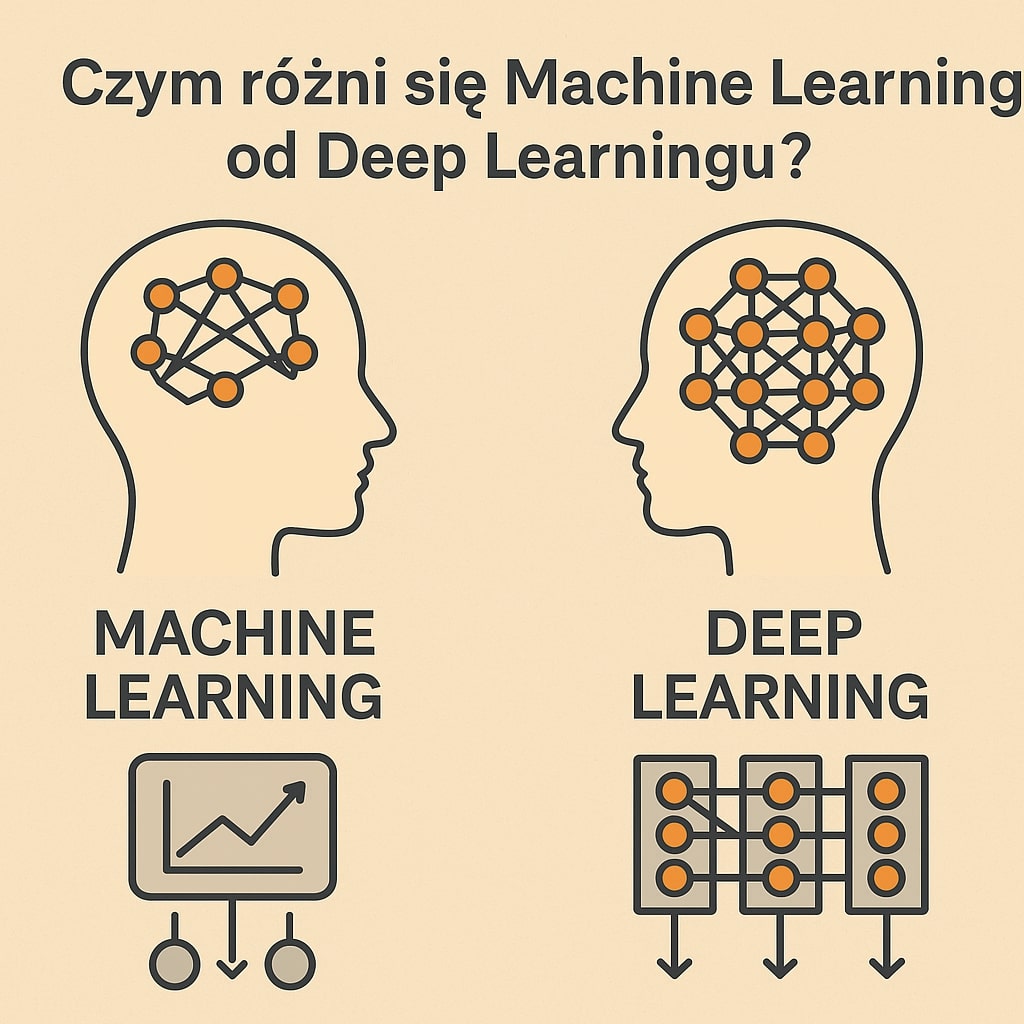
Choć pojęcia Machine Learning (ML) i Deep Learning (DL) są często używane zamiennie, w rzeczywistości reprezentują one różne stopnie zaawansowania i metodyki w obrębie sztucznej inteligencji. Zrozumienie różnic między nimi jest kluczowe dla każdego, kto chce zrozumieć, jak współczesna technologia przetwarza dane.
Spis treści
1. Relacja hierarchiczna: Co jest czym?
Zanim przejdziemy do różnic, należy zrozumieć fundament: Deep Learning to podzbiór Machine Learningu.
- Sztuczna Inteligencja (AI): Najszersze pojęcie, obejmujące każdą technikę, która pozwala komputerom naśladować ludzkie zachowanie.
- Machine Learning (ML): Zbiór metod AI wykorzystujących algorytmy do wyciągania wniosków z danych bez bezpośredniego programowania każdej reguły.
- Deep Learning (DL): Wyspecjalizowana dziedzina ML, która opiera się na wielowarstwowych sztucznych sieciach neuronowych inspirowanych budową ludzkiego mózgu.
2. Inżynieria cech (Feature Engineering)
To najważniejsza różnica techniczna między tymi dwiema dziedzinami.
- W Machine Learningu: Ekspert (człowiek) musi ręcznie wskazać algorytmowi, na jakie cechy danych ma zwrócić uwagę. Jeśli chcemy, aby program rozpoznał samochód, musimy go „nauczyć”, że auto ma koła, światła i określony kształt.
- W Deep Learningu: Sieć neuronowa sama odkrywa istotne cechy. Na pierwszych warstwach rozpoznaje proste krawędzie, na kolejnych kształty, aż w końcu identyfikuje cały obiekt. Proces ten nazywamy automatyczną ekstrakcją cech.
3. Zapotrzebowanie na dane i skalowalność
Dane to paliwo dla obu tych technologii, ale ich „apetyt” jest różny:
- Machine Learning: Dobrze radzi sobie z mniejszymi i średnimi zbiorami danych. Po osiągnięciu pewnego poziomu nasycenia, dodawanie kolejnych danych nie zwiększa już znacząco celności modelu.
- Deep Learning: Wymaga ogromnych ilości danych (Big Data), aby być skutecznym. Co istotne, modele DL skalują się niemal liniowo – im więcej danych im dostarczymy, tym stają się lepsze.
4. Wymagania sprzętowe
Różnica w sposobie przetwarzania danych przekłada się na hardware:
- ML: Algorytmy (np. regresja liniowa, drzewa decyzyjne) są stosunkowo proste obliczeniowo. Większość z nich można trenować na standardowym procesorze (CPU).
- DL: Sieci neuronowe wykonują miliony operacji mnożenia macierzy jednocześnie. Do ich wydajnej pracy niezbędne są jednostki przetwarzania graficznego (GPU) lub dedykowane układy (TPU), które potrafią przetwarzać zadania równolegle.
5. Czas trenowania i czas wnioskowania
Warto rozróżnić czas potrzebny na naukę modelu od czasu jego odpowiedzi:
| Cecha | Machine Learning | Deep Learning |
| Czas trenowania | Krótki (od kilku sekund do kilku godzin). | Długi (od kilku dni do tygodni). |
| Czas wnioskowania | Bardzo szybki. | Może być wolniejszy (zależy od złożoności sieci). |
6. Przejrzystość działania (Black Box vs White Box)
- ML (White/Gray Box): Wiele modeli ML (np. drzewa decyzyjne) jest łatwych do zinterpretowania. Możemy dokładnie prześledzić, dlaczego algorytm podjął taką, a nie inną decyzję.
- DL (Black Box): Sieci neuronowe są niezwykle skomplikowane. Nawet ich twórcy często mają problem z wyjaśnieniem, dlaczego model zaklasyfikował dany obraz w konkretny sposób. Jest to wyzwanie w branżach takich jak medycyna czy prawo.
7. Przykłady zastosowań w świecie rzeczywistym
Wybór między ML a DL zależy od złożoności problemu:
Gdzie króluje Machine Learning?
- Prognozowanie sprzedaży: Przewidywanie popytu na podstawie danych historycznych.
- Filtry antyspamowe: Klasyfikacja wiadomości e-mail.
- Systemy rekomendacji: Sugestie produktów w sklepach internetowych.
Gdzie niezbędny jest Deep Learning?
- Rozpoznawanie obrazu: Systemy FaceID, diagnostyka nowotworów na zdjęciach RTG.
- NLP (Przetwarzanie języka naturalnego): Tłumacze symultaniczni, chatboty (np. ChatGPT).
- Autonomiczne pojazdy: Interpretacja otoczenia przez kamery i sensory w czasie rzeczywistym.
Podsumowanie: Którą metodę wybrać?
Wybór zależy od Twoich zasobów i celu. Jeśli dysponujesz uporządkowanymi danymi (np. tabele w Excelu) i ograniczoną mocą obliczeniową, Machine Learning będzie strzałem w dziesiątkę. Jeśli jednak Twoim wyzwaniem są dane nieustrukturyzowane (obrazy, dźwięk, tekst) i masz dostęp do potężnych serwerów, Deep Learning pozwoli Ci osiągnąć wyniki nieosiągalne dla klasycznych metod.