Rodzaje uczenia maszynowego: nadzorowane, nienadzorowane i wzmacniane
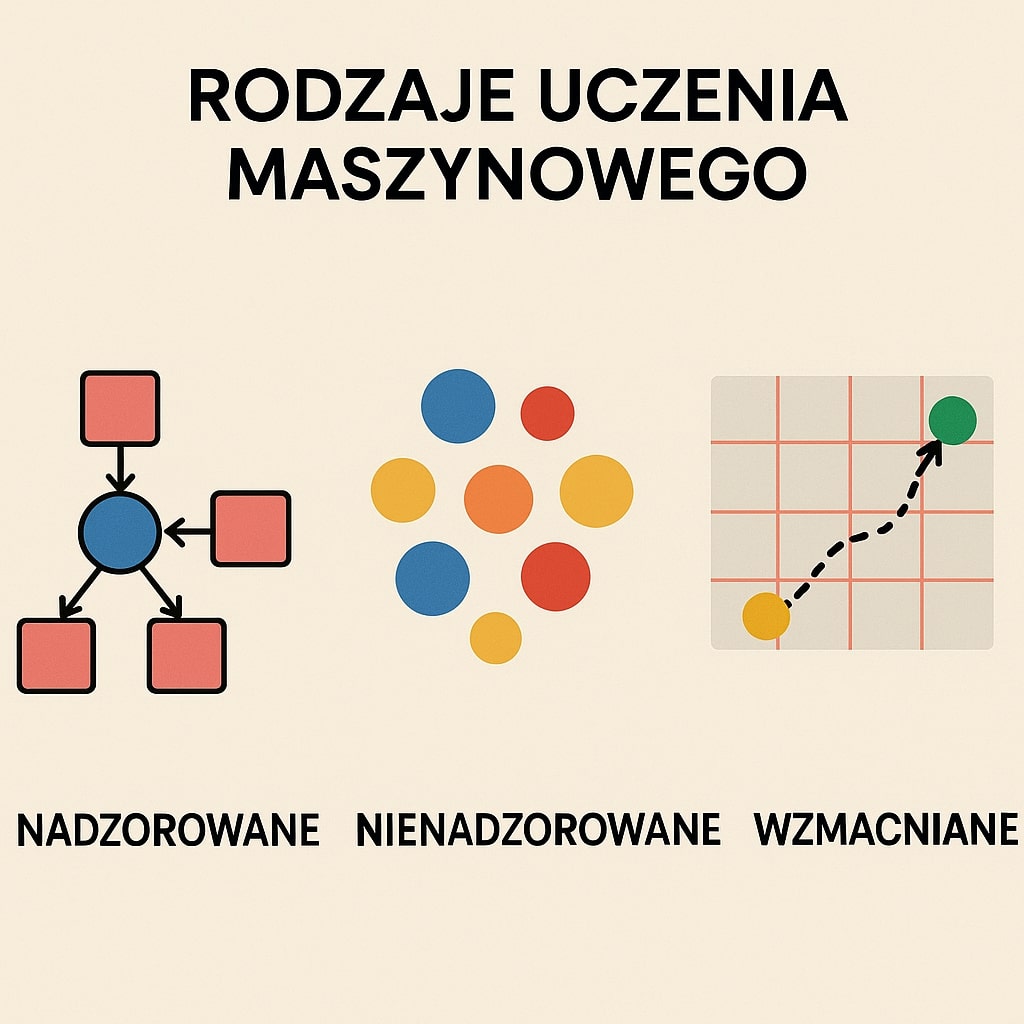
Uczenie maszynowe to fundamentalna gałąź sztucznej inteligencji, która pozwala komputerom uczyć się na podstawie danych bez potrzeby bezpośredniego programowania każdej możliwej sytuacji. Choć wszystkie metody uczenia maszynowego mają wspólny cel – nauczenie maszyny wykonywania określonych zadań – różnią się one sposobem, w jaki ten cel osiągają.
Wyobraź sobie, że uczysz dziecko rozróżniać zwierzęta. Możesz pokazywać mu zdjęcia i mówić „to jest pies”, „to jest kot” (uczenie nadzorowane). Możesz też pokazać mu dziesiątki zdjęć zwierząt i pozwolić mu samemu odkryć, że niektóre zwierzęta są do siebie podobne (uczenie nienadzorowane). Albo możesz nagradzać je za prawidłowe odpowiedzi i karać za błędne (uczenie przez wzmacnianie). Podobnie działa uczenie maszynowe – różne podejścia do tego samego problemu.
Spis treści
1. Uczenie nadzorowane – nauka z nauczycielem
Uczenie nadzorowane to najbardziej intuicyjna metoda uczenia maszynowego. Polega ona na treningu modelu na podstawie danych, które są już odpowiednio opisane – etykietowane. To tak, jakbyś uczył się do egzaminu z gotowym zestawem pytań i odpowiedzi.
1.1. Jak to działa?
W uczeniu nadzorowanym dostarczamy modelowi parę: dane wejściowe (features) i oczekiwaną odpowiedź (etykietę). Model analizuje te pary, szuka wzorców i uczy się przewidywać prawidłowe odpowiedzi dla nowych, nieznanych wcześniej danych. Proces ten wymaga danych treningowych, które muszą być starannie etykietowane.
Wyobraź sobie, że chcesz nauczyć komputer rozpoznawać spam. Dostarczasz mu tysiące wiadomości email, gdzie przy każdej napisane jest „spam” lub „nie spam”. Algorytm analizuje cechy tych wiadomości – słowa, które się w nich pojawiają, długość, nadawcę – i uczy się rozpoznawać wzorce charakterystyczne dla spamu.
1.2. Zastosowania uczenia nadzorowanego
Uczenie nadzorowane dominuje w praktycznych zastosowaniach AI. Znajdziemy je w:
Rozpoznawaniu obrazów – gdy uczymy system rozróżniać zdjęcia psów od kotów, diagnozować choroby na podstawie zdjęć rentgenowskich czy rozpoznawać twarze.
Przetwarzaniu języka – w tłumaczeniu maszynowym, analizie sentymentu, rozpoznawaniu nazw własnych w tekstach.
Prognozowaniu – przewidywanie cen akcji, pogody, prawdopodobieństwa rezygnacji klientów czy wykrywanie oszustw.
Diagnostyce medycznej – rozpoznawanie chorób na podstawie objawów, analiza wyników badań, wspomaganie decyzji lekarskich.
1.3. Wyzwania uczenia nadzorowanego
Największym problemem uczenia nadzorowanego jest potrzeba dużych ilości etykietowanych danych. Proces etykietowania jest czasochłonny, kosztowny i podatny na błędy ludzkie. To właśnie dlatego powstały metody jak active learning, gdzie model sam wskazuje, które dane powinny zostać oznaczone przez człowieka.
Kolejnym wyzwaniem jest overfitting – sytuacja, gdy model „zakuwa” dane treningowe na pamięć i nie radzi sobie z nowymi przypadkami. Wymaga to stosowania technik regularyzacji i odpowiedniego podziału danych na treningowe, walidacyjne i testowe.
2. Uczenie nienadzorowane – odkrywanie ukrytych wzorców
Uczenie nienadzorowane to podejście, w którym algorytm sam odkrywa strukturę i wzorce w danych, bez podawania mu gotowych odpowiedzi. To jak wyprawa odkrywcza – nie wiesz, co znajdziesz, ale szukasz czegoś interesującego.
2.1. Jak to działa?
W uczeniu nienadzorowanym dostarczamy modelowi tylko dane wejściowe, bez etykiet. Algorytm analizuje dane i próbuje znaleźć w nich ukryte struktury, podobieństwa lub anomalie. Nie mówimy mu, czego szukać – on sam decyduje, co jest istotne.
Najczęstsze techniki uczenia nienadzorowanego to:
Grupowanie (clustering) – algorytm sam dzieli dane na grupy podobnych elementów. Przykładowo, analizując zachowania klientów sklepu internetowego, może automatycznie wykryć, że istnieją „polujący na promocje”, „kupujący premium” i „okazjonalni odwiedzający”.
Redukcja wymiarowości – upraszczanie złożonych danych przy zachowaniu najważniejszych informacji. Techniki jak PCA pozwalają zamienić dane z setkami cech na ich uproszczoną reprezentację.
Wykrywanie anomalii – identyfikowanie nietypowych wzorców, które odbiegają od normy. Wykorzystywane w wykrywaniu oszustw finansowych czy awarii systemów.
2.2. Zastosowania uczenia nienadzorowanego
Uczenie nienadzorowane świetnie sprawdza się tam, gdzie etykietowanie danych jest niemożliwe lub nieopłacalne:
Segmentacja klientów – automatyczne grupowanie klientów według zachowań zakupowych, pozwalające na lepszą personalizację oferty.
Systemy rekomendacji – odkrywanie ukrytych preferencji użytkowników i grupowanie podobnych produktów czy treści.
Kompresja danych – autoencodery uczą się efektywnie reprezentować dane w bardziej zwartej formie.
Eksploracja danych – gdy nie wiemy jeszcze, czego dokładnie szukamy, ale chcemy odkryć ciekawe wzorce w dużych zbiorach danych.
2.3. Wyzwania uczenia nienadzorowanego
Największym problemem uczenia nienadzorowanego jest brak obiektywnej miary sukcesu. Jak ocenić, czy grupowanie jest „dobre”? Różne algorytmy mogą znaleźć zupełnie różne, ale równie sensowne wzorce w tych samych danych.
Dodatkowo, wyniki uczenia nienadzorowanego często wymagają interpretacji przez eksperta dziedzinowego. Sam fakt, że algorytm znalazł 7 grup klientów, nie mówi nam jeszcze, co te grupy charakteryzuje i jak z tej wiedzy skorzystać.
3. Uczenie przez wzmacnianie – nauka przez trial and error
Uczenie przez wzmacnianie (reinforcement learning) to metoda inspirowana tym, jak uczą się zwierzęta i ludzie – poprzez interakcję ze środowiskiem i system nagród oraz kar. To najbardziej „inteligentna” forma uczenia maszynowego, pozwalająca systemom na autonomiczne podejmowanie decyzji.
3.1. Jak to działa?
W uczeniu przez wzmacnianie agent (nasz model) działa w pewnym środowisku. Wykonuje akcje, obserwuje ich skutki i otrzymuje nagrody lub kary. Jego celem jest nauczenie się strategii (policy), która maksymalizuje sumę nagród w długim okresie.
Kluczowe elementy:
- Agent – system uczący się (np. robot, program gry)
- Środowisko – świat, w którym agent działa
- Stan – aktualna sytuacja w środowisku
- Akcja – to, co agent może zrobić
- Nagroda – feedback od środowiska
Wyobraź sobie robota uczącego się chodzić. Na początku pada po każdym kroku. Otrzymuje niewielką karę za każde upadek. Za każdy udany krok dostaje nagrodę. Stopniowo uczy się, które ruchy prowadzą do sukcesu, a które do porażki. W przeciwieństwie do uczenia nadzorowanego, nikt nie pokazuje mu „poprawnego” sposobu chodzenia – odkrywa go sam poprzez eksperymenty.
3.2. Zastosowania uczenia przez wzmacnianie
Uczenie przez wzmacnianie rewolucjonizuje dziedziny wymagające podejmowania sekwencji decyzji:
Gry – AlphaGo pokonał mistrza świata w go, a systemy AI osiągają nadludzki poziom w grach komputerowych jak Dota 2 czy StarCraft.
Robotyka – roboty uczące się manipulacji obiektami, chodzenia, nawigacji w złożonych środowiskach.
Pojazdy autonomiczne – samochody autonomiczne uczące się podejmowania decyzji w ruchu drogowym.
Handel algorytmiczny – systemy tradingowe optymalizujące strategie inwestycyjne na podstawie reakcji rynku.
Zarządzanie zasobami – optymalizacja zużycia energii w centrach danych, zarządzanie ruchem w miastach, planowanie tras dostaw.
3.3. Wyzwania uczenia przez wzmacnianie
Uczenie przez wzmacnianie jest potężne, ale ma swoje ograniczenia. Wymaga ogromnej liczby prób i błędów – agent musi doświadczyć wielu sytuacji, aby nauczyć się dobrej strategii. To nie jest problem w symulacjach komputerowych, ale staje się nim w świecie rzeczywistym, gdzie eksperymenty są kosztowne lub niebezpieczne.
Kolejnym wyzwaniem jest reward hacking – sytuacja, gdy agent znajduje „kruczki” pozwalające maksymalizować nagrodę bez wykonywania zamierzonego zadania. Słynny przykład: robot uczący się biegać nauczył się… przewracać do przodu, bo w ten sposób szybciej przemieszczał swój środek masy w pożądanym kierunku.
4. Uczenie półnadzorowane i inne podejścia hybrydowe
W praktyce granice między tymi trzema rodzajami uczenia nie są ostre. Powstały metody hybrydowe łączące zalety różnych podejść.
4.1. Uczenie półnadzorowane
Uczenie półnadzorowane łączy niewielką ilość danych etykietowanych z dużą ilością danych nieetykietowanych. To praktyczne rozwiązanie problemu kosztownego etykietowania – używamy kilku tysięcy opisanych przykładów i milionów nieopisanych, a model uczy się z obu źródeł.
Przykład: mamy 1000 zdiagnozowanych zdjęć rentgenowskich i 100 000 nieopatrzonych. Model uczy się podstawowych wzorców z etykietowanych danych, a potem odkrywa dodatkowe struktury w nieetykietowanych.
4.2. Self-supervised learning
Self-supervised learning to technika, gdzie model sam generuje etykiety z dostępnych danych. To podejście napędza współczesne duże modele językowe – uczą się przewidywać brakujące słowa w tekście, co nie wymaga ręcznego etykietowania.
4.3. Transfer learning
Transfer learning polega na wykorzystaniu wiedzy z jednego zadania do rozwiązania innego. Model wytrenowany na rozpoznawaniu milionów zdjęć może być dostrojony do specjalistycznego zadania, jak diagnozowanie chorób skóry, używając już tylko kilku tysięcy specjalistycznych przykładów.
5. Które podejście wybrać?
Wybór odpowiedniej metody uczenia zależy od specyfiki problemu:
Uczenie nadzorowane, gdy:
- Masz dostęp do dużej ilości etykietowanych danych
- Znasz dokładnie, jaki wynik chcesz uzyskać
- Problem dotyczy klasyfikacji lub regresji
- Jakość predykcji jest krytyczna
Uczenie nienadzorowane, gdy:
- Nie masz etykietowanych danych lub ich przygotowanie jest niemożliwe
- Chcesz odkryć ukryte wzorce w danych
- Nie wiesz z góry, czego szukasz
- Potrzebujesz eksploracji lub kompresji danych
Uczenie przez wzmacnianie, gdy:
- Problem wymaga sekwencji decyzji
- Możesz zdefiniować jasny system nagród
- Masz dostęp do symulatora lub taniego środowiska testowego
- Optymalizujesz długoterminowe efekty, nie pojedyncze decyzje
Podsumowanie
Trzy główne rodzaje uczenia maszynowego – nadzorowane, nienadzorowane i przez wzmacnianie – reprezentują fundamentalnie różne podejścia do tego samego celu: nauczenia maszyn wykonywania zadań bez bezpośredniego programowania. Uczenie nadzorowane daje najdokładniejsze wyniki, ale wymaga kosztownego etykietowania. Uczenie nienadzorowane odkrywa ukryte wzorce bez nadzoru, ale jego wyniki są trudniejsze do oceny. Uczenie przez wzmacnianie pozwala na autonomiczne podejmowanie decyzji, ale wymaga wielu eksperymentów.
W praktyce granice między tymi metodami się zacierają. Nowoczesne systemy AI często łączą różne podejścia, wykorzystując ich mocne strony. Duże modele językowe używają self-supervised learning w pre-treningu, uczenia nadzorowanego w fine-tuningu i RLHF w dostrajaniu do ludzkich preferencji.
Zrozumienie tych trzech paradygmatów to fundament dla każdego, kto chce pracować ze sztuczną inteligencją. To właśnie one określają, jak współczesne systemy AI uczą się rozwiązywać problemy – od rozpoznawania kotów na zdjęciach, przez grupowanie klientów, po prowadzenie autonomicznych pojazdów.