Computer Vision: Jak maszyny „widzą” obrazy?

Wyobraź sobie, że pokazujesz zdjęcie kota swojemu pięcioletniemu dziecku. Dziecko natychmiast rozpoznaje zwierzę, wskazuje na niego palcem i mówi „kotek!”. Ten proces wydaje się banalnie prosty – w końcu ludzie rozpoznają obrazy od niemowlęctwa. Ale dla maszyny? To jedno z najtrudniejszych wyzwań w historii sztucznej inteligencji.
Computer vision, czyli wizja komputerowa, to dziedzina AI zajmująca się uczeniem maszyn rozumienia i interpretowania świata wizualnego. Dzięki niej samochody autonomiczne widzą drogę, smartfony rozpoznają twarze właścicieli, a aplikacje medyczne wykrywają nowotwory na zdjęciach rentgenowskich. Ale jak dokładnie maszyny „uczą się” widzieć?
Spis treści
1. Od pikseli do znaczenia: podstawy wizji komputerowej
Dla człowieka obraz to całość – widzimy kota, dom, drzewo. Dla komputera obraz to jedynie gigantyczna tabela liczb. Każdy piksel ma swoją wartość określającą kolor (w modelu RGB) lub jasność (w skali szarości). Zdjęcie o rozdzielczości 1920×1080 pikseli to ponad 2 miliony liczb, które komputer musi przetworzyć i zinterpretować.
Pierwsze systemy computer vision działały na zasadzie ręcznie zaprogramowanych reguł: „jeśli piksel jest ciemniejszy niż sąsiedni, to może to być krawędź obiektu”. Takie podejście, zwane klasyczną wizją komputerową, wymagało od inżynierów definiowania każdej cechy, którą maszyna powinna wykrywać. Był to proces żmudny, czasochłonny i… niezbyt skuteczny.
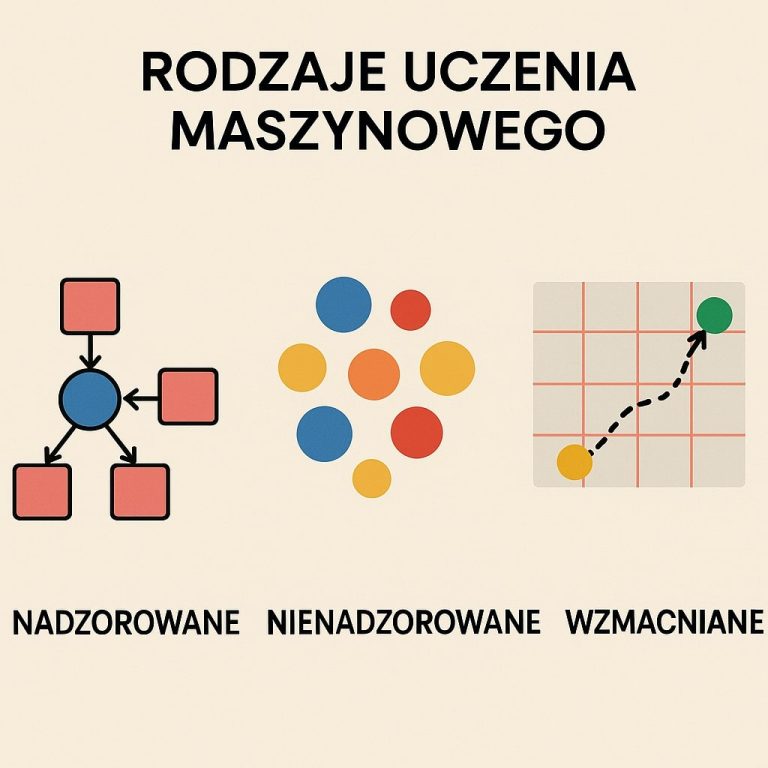
Prawdziwy przełom nastąpił wraz z uczeniem głębokim i sieciami neuronowymi. Zamiast instruować komputer „jak” ma widzieć, pokazujemy mu tysiące przykładów i pozwalamy mu samodzielnie nauczyć się wzorców.
2. Convolutional Neural Networks: rewolucja w rozpoznawaniu obrazów
Kluczem do sukcesu współczesnej wizji komputerowej są konwolucyjne sieci neuronowe (CNN). Te specjalistyczne architektury zostały zaprojektowane specjalnie do przetwarzania danych wizualnych i – co ciekawe – ich struktura jest inspirowana działaniem ludzkiego układu wzrokowego.
CNN działają na zasadzie warstw przetwarzających obraz na coraz wyższym poziomie abstrakcji. Pierwsza warstwa wykrywa proste elementy jak krawędzie i linie. Druga łączy je w podstawowe kształty. Trzecia rozpoznaje bardziej złożone struktury – uszy, oczy, koła. Ostatnia warstwa łączy wszystkie informacje i mówi: „to jest kot” albo „to jest samochód”.
Tajemnicą skuteczności CNN jest operacja splotu (convolution). Zamiast analizować każdy piksel osobno, sieć używa małych filtrów (zwykle 3×3 lub 5×5 pikseli), które „przesuwają się” po całym obrazie, wykrywając lokalne wzorce. Te same filtry są używane w różnych częściach obrazu, co sprawia, że sieć rozpozna kota niezależnie od tego, czy znajduje się w lewym górnym, czy prawym dolnym rogu zdjęcia.
Po warstwie konwolucyjnej następuje zwykle pooling – proces zmniejszania rozdzielczości, który pomaga sieci skupić się na najważniejszych cechach obrazu i zmniejsza wymagania obliczeniowe.
3. Jak maszyny uczą się widzieć: trening na milionach przykładów
Proces uczenia CNN przypomina nauczanie dziecka rozpoznawania zwierząt. Pokazujesz tysiące zdjęć kotów, psów, koni – każde z etykietą „to jest kot”, „to jest pies”. Sieć stopniowo dostosowuje swoje wagi i parametry, ucząc się, które cechy są charakterystyczne dla danej kategorii.
Kluczowe elementy procesu treningu to:
Ogromne zbiory danych: Najlepsze modele trenowane są na milionach obrazów. Słynny zbiór ImageNet zawiera ponad 14 milionów opatrzonych etykietami zdjęć w 20 tysiącach kategorii. To właśnie na ImageNet trenowano przełomowe architektury jak ResNet, która w 2015 roku po raz pierwszy przewyższyła człowieka w rozpoznawaniu obiektów.
Wsteczna propagacja błędu: Sieć porównuje swoje przewidywania z prawidłowymi odpowiedziami, oblicza błąd i aktualizuje swoje parametry, by następnym razem działać lepiej. Ten proces backpropagation powtarza się miliony razy podczas treningu.
Augmentacja danych: By sieć była bardziej odporna na różne warunki, treningowe obrazy są sztucznie modyfikowane – obracane, przycinane, rozjaśniane, odbijane lustrzanie. Technika ta, zwana data augmentation, skutecznie zwiększa różnorodność zbioru treningowego bez zbierania nowych danych.
Transfer learning: Nie zawsze trzeba trenować model od zera. Często wykorzystuje się transfer learning – bierzemy sieć wytrenowaną na ImageNet i dostrajamy ją do naszego specyficznego zadania, np. rozpoznawania chorób na zdjęciach rentgenowskich.
4. Od klasyfikacji do zrozumienia sceny: zadania computer vision
Computer vision to znacznie więcej niż tylko odpowiadanie na pytanie „co jest na tym zdjęciu?”. Współczesne systemy potrafią wykonywać coraz bardziej zaawansowane zadania.
Klasyfikacja obrazów to najprostsza forma – model przypisuje całemu obrazowi jedną lub więcej etykiet. „To jest pies rasy golden retriever”. Proste, ale potężne.
Object detection (wykrywanie obiektów) idzie o krok dalej. Nie tylko rozpoznaje, co jest na obrazie, ale także określa położenie każdego obiektu, rysując wokół niego bounding box – prostokąt oznaczający wykryty obiekt. Systemy jak YOLO (You Only Look Once) potrafią wykrywać i klasyfikować dziesiątki obiektów na pojedynczym obrazie w czasie rzeczywistym.
Segmentacja obrazu (image segmentation) to jeszcze wyższy poziom precyzji. Zamiast prostokątów, model przypisuje każdy piksel obrazu do konkretnej kategorii – „ten piksel to niebo, ten to drzewo, ten to droga”. W autonomicznych pojazdach to krytyczna funkcja – samochód musi dokładnie wiedzieć, gdzie kończy się chodnik, a zaczyna jezdnia.
Pose estimation (wykrywanie pozy ciała) analizuje położenie ludzkiego ciała w przestrzeni, identyfikując kluczowe punkty jak stawy, głowa, biodra. Wykorzystywane jest w sporcie, grach wideo i aplikacjach fitness.
Face recognition (rozpoznawanie twarzy) to oddzielna specjalizacja, która nie tylko wykrywa twarze na zdjęciach, ale potrafi je identyfikować i weryfikować. To technologia, która odblokowuje Twój telefon i… budzi spore kontrowersje dotyczące prywatności.
5. Vision Transformers: nowa era architektury
Przez lata CNN dominowały w computer vision, ale około 2020 roku pojawiła się nowa architektura zaczerpnięta z przetwarzania języka naturalnego – Vision Transformer (ViT).
Zamiast traktować obraz jako ciągłą strukturę pikseli, ViT dzieli go na małe fragmenty (patches), które następnie przetwarza podobnie jak tokeny w modelach językowych. Kluczowy jest tu mechanizm attention, który pozwala modelowi skupić się na najbardziej istotnych częściach obrazu i zrozumieć relacje między różnymi regionami.
ViT wykazują imponujące wyniki, często przewyższając klasyczne CNN, szczególnie gdy trenowane są na ogromnych zbiorach danych. Jednak wymagają znacznie większych zasobów obliczeniowych niż tradycyjne architektury.
6. Multimodalne modele: gdy obraz spotyka tekst
Najnowszą rewolucją w computer vision są modele multimodalne łączące rozumienie obrazu z przetwarzaniem języka naturalnego. Przełomowy był CLIP od OpenAI, który nauczył się rozumieć relacje między obrazami a opisującym je tekstem.
Dzięki CLIP możesz wyszukiwać obrazy używając dowolnych opisów – „czerwony samochód zaparkowany pod drzewem o zachodzie słońca” – bez konieczności wcześniejszego etykietowania każdego zdjęcia takimi szczegółowymi tagami. Model sam rozumie znaczenie opisu i znajduje pasujące obrazy.
Te same zasady stoją za generatywnymi modelami obrazów jak Stable Diffusion czy DALL-E, które działają w odwrotnym kierunku – tworzą obrazy na podstawie opisów tekstowych.
7. Wyzwania i ograniczenia współczesnej wizji komputerowej
Mimo ogromnego postępu, computer vision wciąż boryka się z istotnymi wyzwaniami. Systemy świetnie rozpoznają obiekty w standardowych warunkach, ale mogą zawodzić przy nietypowym oświetleniu, nietypowych kątach czy częściowym zasłonięciu obiektów.
Adversarial attacks (ataki adversarialne) pokazują, jak łatwo można oszukać sieci neuronowe. Dodanie niewidocznych dla człowieka szumów do obrazu może sprawić, że model rozpozna pandę jako gibona czy znak stop jako znak ograniczenia prędkości. To poważny problem szczególnie w kontekście autonomicznych pojazdów.
Bias (stronniczość algorytmów) to kolejne wyzwanie. Systemy rozpoznawania twarzy mogą gorzej działać dla osób o ciemniejszej karnacji, jeśli były trenowane głównie na zdjęciach osób białych. Problem ten budzi poważne obawy etyczne, szczególnie gdy takie systemy używane są przez organy ścigania.
Wyjaśnialność to fundamentalny problem. Nawet najlepsze modele to wciąż czarne skrzynki – trudno zrozumieć, dlaczego model podjął konkretną decyzję. W aplikacjach medycznych czy systemach bezpieczeństwa to nieakceptowalne. Dziedzina Explainable AI (XAI) próbuje rozwiązać ten problem, ale wciąż jest długa droga przed nami.
8. Praktyczne zastosowania: gdzie computer vision zmienia świat
Computer vision przestała być technologią laboratoryjną – jest wszędzie wokół nas.
W medycynie systemy oparte na CNN analizują zdjęcia rentgenowskie, tomografię komputerową i skany rezonansu magnetycznego, często wykrywając choroby skuteczniej niż doświadczeni radiolodzy. AlphaFold od DeepMind przewiduje struktury białek, co otwiera nowe możliwości w projektowaniu leków.
W przemyśle systemy kontroli jakości automatycznie wykrywają wady produktów na liniach produkcyjnych z prędkością i precyzją niemożliwą dla człowieka. Roboty przemysłowe używają computer vision do precyzyjnej manipulacji obiektami.
W rolnictwie drony wyposażone w kamery i AI monitorują zdrowie upraw, wykrywają choroby roślin i optymalizują nawadnianie, zwiększając plony przy jednoczesnym zmniejszeniu zużycia wody i pestycydów.
W retailu sklepy bezobsługowe jak Amazon Go używają setek kamer i zaawansowanych algorytmów, by śledzić, jakie produkty klienci biorą z półek, automatycznie naliczając opłaty bez konieczności przechodzenia przez kasę.
W bezpieczeństwie monitoring wizyjny ewoluuje od prostego nagrywania do aktywnej analizy – wykrywania podejrzanych zachowań, rozpoznawania tablic rejestracyjnych, identyfikowania osób.
9. Przyszłość: dokąd zmierza wizja komputerowa
Najbliższa przyszłość computer vision będzie należeć do modeli multimodalnych łączących obraz, tekst, dźwięk, a nawet dane z czujników w spójne rozumienie kontekstu. Następnym krokiem są world models – systemy budujące wewnętrzną reprezentację trójwymiarowego świata i zasad nim rządzących.
Vision-Language-Action (VLA) models już teraz pozwalają robotom rozumieć polecenia w języku naturalnym i wykonywać je w fizycznym świecie. „Weź czerwony kubek ze stołu i postaw go na półce” – robot widzi kubek, planuje trajektorię ruchu i wykonuje zadanie.
Rozwój neuromorphic computing – sprzętu naśladującego fizyczną strukturę ludzkiego mózgu – może przynieść systemy computer vision zużywające ułamek obecnej energii, co umożliwi zaawansowaną analizę obrazu nawet w urządzeniach IoT.
Podsumowanie: nowa era „widzenia” maszyn
Computer vision przeszła długą drogę od prostych algorytmów wykrywających krawędzie do zaawansowanych systemów rozumiejących kontekst i znaczenie obrazów. Dzisiejsze modele nie tylko rozpoznają obiekty – potrafią opisywać sceny, odpowiadać na pytania o zawartość obrazu, a nawet generować nowe obrazy na podstawie opisów.
Ale to dopiero początek. W miarę jak AI ewoluuje, computer vision stanie się jeszcze bardziej wszechobecna i potężna. Być może już niedługo maszyny będą „widzieć” lepiej niż my – nie tylko w sensie rozpoznawania obiektów, ale prawdziwego rozumienia wizualnego świata.
Pytanie brzmi: czy jako społeczeństwo jesteśmy gotowi na świat, w którym maszyny obserwują i interpretują wszystko, co dzieje się wokół nas? To pytanie techniczne, ale przede wszystkim etyczne i społeczne. I na nie musimy znaleźć odpowiedź zanim technologia wyprzedzi nasze możliwości jej kontrolowania.